The Developer’s Edge, Building a Smarter Financial Assistant with Gemini AI
January 01, 2025
Photos from Josh Appel on Unsplash
I put my finance records in Notion. But it could be better.
Artificial Intelligence has a rapid adoption rate these days. Even we as common folks already use it on a daily basis, hovering from ChatGPT, Gemini, and the latest one Meta AI in Instagram and WhatsApp.
Ever wondered how you can integrate these powerful AIs into your own application? We’re about to dive into just that with my case — Building a financial assistant with AI —.
This article will cover how Artificial Intelligence works for Large Language Models (LLM) such as ChatGPT and Gemini, the Gemini API itself, and how I integrate it into a web application.
How AI Works
To make the best use of AI, we’ll need to know what part they can help us with and how they operate. I’m trying my best to summarize how they work on the top level.
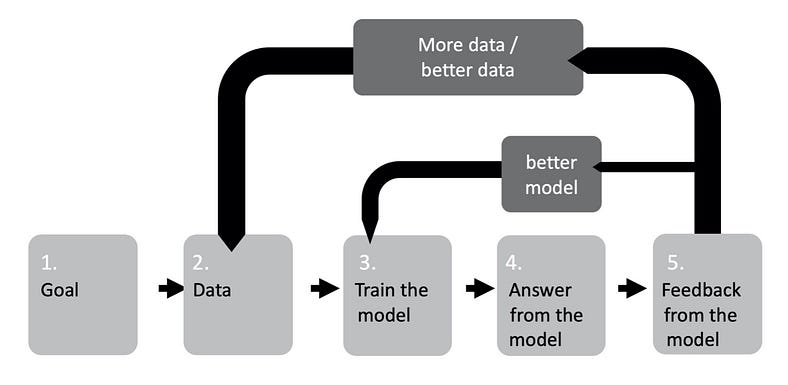
Iterative process of how the model inside AI works. Credits to Source
{kind=link}
We humans have been putting and transferring data over the internet for the past years in lots of fields of expertise. This defines the ‘Goal’ part of any field, such as Healthcare, education, e-commerce, property, etc.
Data Gathering
Companies that are perceptive and have the manpower, can gather lots of data from their own analytics dashboard, web scraping, or even gathering real user feedback.
These data then become the main ‘fuel’ of how AI will be implemented. Knowing this, it is unsurprising that data is the new ‘oil’ and how rapid AI development is.
Data Cleaning
More data generally means more noise. These noises could negatively affect your training/testing data either making the model overfit or underfit (more on this later). Below are the lists that should be considered to make your data clean:
- Remove duplicates
- Convert data type (e.g. number, decimals)
Clear and consistent formatting (e.g. capitals, date formats, currencies, etc.)
- Handle missing values
- Language Translation
- Remove irrelevant data
- Standardize capitalization
- Detect and remove Outliers
It’s worth mentioning that handling outliers will require some statistical knowledge (by using box plots and scatter plots). But initially, the bold ones from the list should be in your first nature when doing data cleaning.
Data Splitting
After the data is clean, we need to split those data into training data and testing data. We need to find the sweet spot ratio of both with our cleaned data. There are two conditions if we fail to do so:
Overfitting: If the training set is too large, the model may overfit to the training data, meaning it performs well on the training set but poorly on unseen data.
Underfitting: If the training set is too small, the model may not learn enough patterns in the data and perform poorly on both training and testing sets.
Reflecting on my experience and from what I’ve seen on the internet, generally, the split is 80% training data and 20% training data. But do have your time finding the acceptable spot for the desired accuracy of the model. After all, it really depends on your use case, datasets, and model reference if any.
Finding the best balance requires knowledge, and a bunch of trials and errors.
Model Training
Each machine learning model has a different purpose and approach to how they process ‘learn’. In LLMs (Large Language Model), This process involves:
- Breaking down the text into smaller units
- Feeding it into a transformer neural network
Iteratively adjusting the model’s parameters to minimize prediction errors. This allows the model to learn complex patterns and relationships within human language, enabling it to generate human-like text, translate languages, and perform many other language-related tasks.
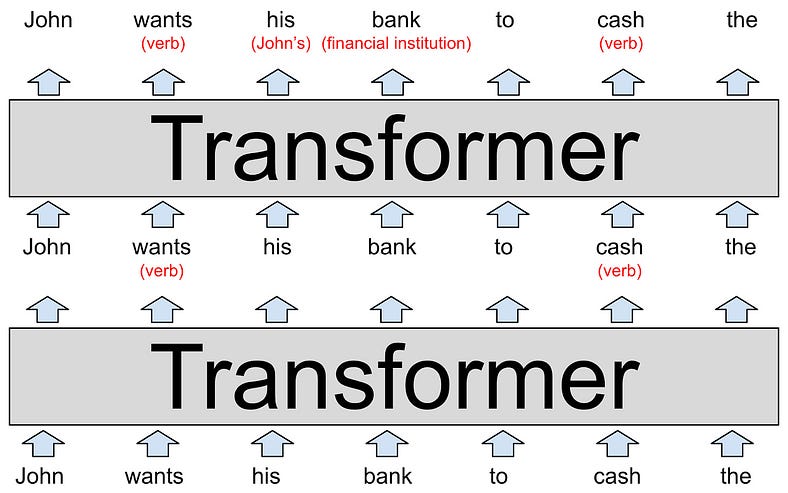
The model was given a sentence, and each of the neuron network layers (transformer) specifies each word’s role for that sentence context.
I found a great article on how LLMs process learning by quantifying the
weight of each word as vectors to determine and predict what the next word is
depending on the given context. Greatly explained Timothy B.
Lee and Sean
Trott in Large language models, explained
with a minimum of math and
jargon.
After going through the process of Data Gathering all the way to Model Training. The result will then be reviewed by humans. Flagging which response is acceptable or not based on our acceptance criteria.
Advanced models from major players (ChatGPT, Gemini, etc.) have large data pools for training and validating their AI models for various outputs — in our case, text generation —, and have lots of researchers and Data Scientists to make the model give reliable outputs.
Data Security
Data and user privacy are also concerns when utilizing AI for daily use. One thing that we can control is how much data we give to them to still function and give the expected result we need.

What we give to the chat, will be used to train the model.
As we use this technology, bear in mind that our inputs will be used to train the AI model and might be reviewed by humans iteratively.
Gemini API
You still read until this point? Awesome.
I can’t stress more how we’re fortunate enough to have these ready-to-use
models, considering their complexity.
Now that we know how those work behind the scenes, We’re gonna use one of the widely-used models out there with ease.
I’m using Gemini for this project because the barrier is relatively lower than using models from OpenAI as they no longer provide a free tier. Let’s see how we use this for our benefit:
The first thing we will need is the API Key for Gemini API. This key will be included in each request we make to the Gemini endpoints later on. We can get our first API key by visiting aistudio.google.com.
Snapshot of aistudio.google.com for everytime you visit the website.
- Click the ‘Get API Key’ button in the image attached below.
Creating API key for your first project in Google AI Studio
Save the API key inside your .env files. You can always check the API key by accessing the same page.
- See available models and their restrictions
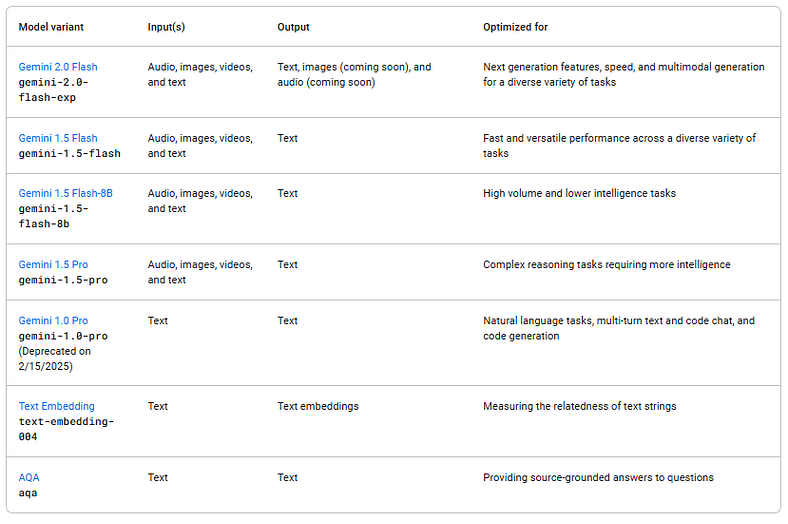
Available models to choose from when using Gemini API. Source: Model Variants
There are quite a lot of models we can use. We can choose it depending on each use case. For this enhanced finance tracker app, I’m using Gemini 1.5 Flash as it will be sufficient for giving financial advice.
Other than that, we also need to consider the token and rate limits as this will have a huge impact on how we design the user flow and experience.
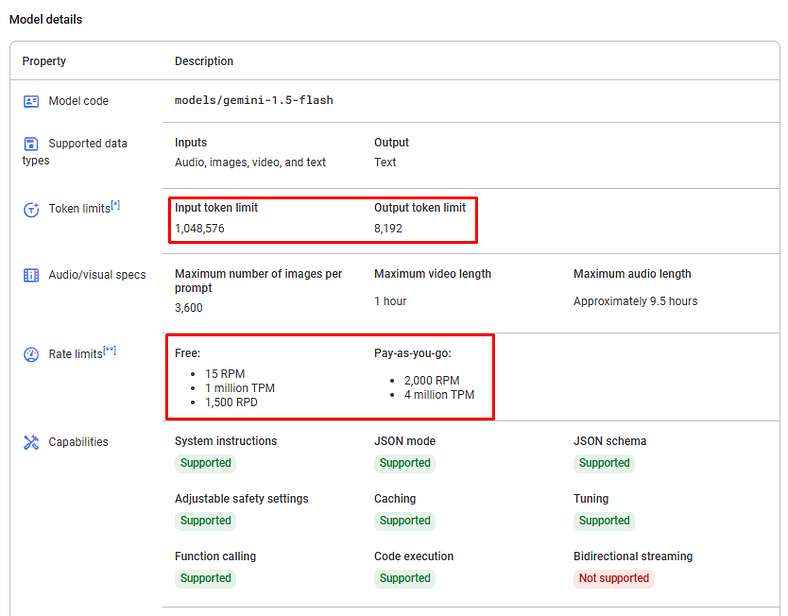
RPM: Requests per minute | TPM: Tokens per minute | RPD: Requests per day | TPD: Tokens per day
If you are keen on building personal projects, pay attention to the free tiers. We are limited to making 15 requests per minute and 1500 Requests each day.
Even as a solopreneur, we also need to consider the pay-as-you-go plan. Make sure to design the application to make the cash flow positive, not to overspend it on one feature.
- Making your first API Call
The first thing we’d notice after creating API key is this picture in the dashboard
For a quick check, we can use Postman and copy-paste that cURL Request alongside the API key we’ve just created.
Input the cURL request and the API Key in the Postman
The cURL request with fetch API is working. But it’s quite troublesome to form the payload (unless you’re keen on Data Science and Algorithm I guess it’s just another leetcode challenge for you).
Not to mention, it’s not that scalable if we want to put more input context into the model.
Why do we want more input context? Generally, users expect the AI model to remember their conversation right? We’ll need to put those into the payload too.
There should be a better alternative.
You can try installing this google/generative-ai.
- Install library google/generative-ai
Well yes, the developers sure are pumping this tech. Taken 28/12/2024
This is a quick example of how you can make your API request with this library.
Let me show you more about what those mean in my codebase:
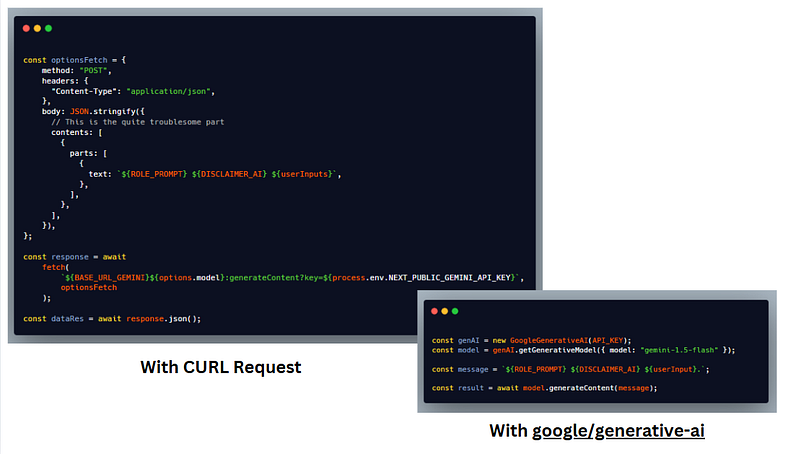
Well yes, it’s quite a difference
I’ve built the UI to test the latest approach, and it turns out like this:
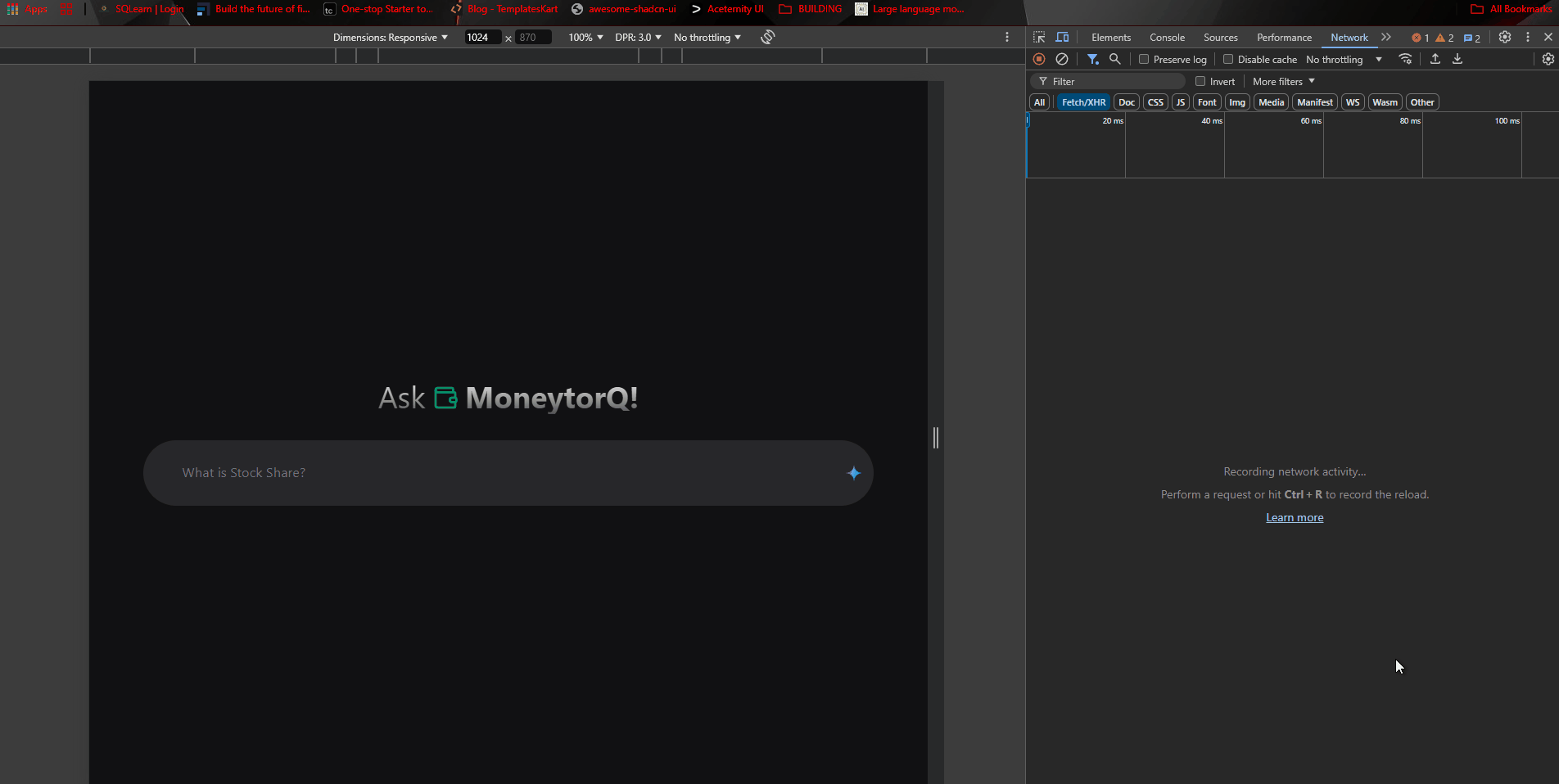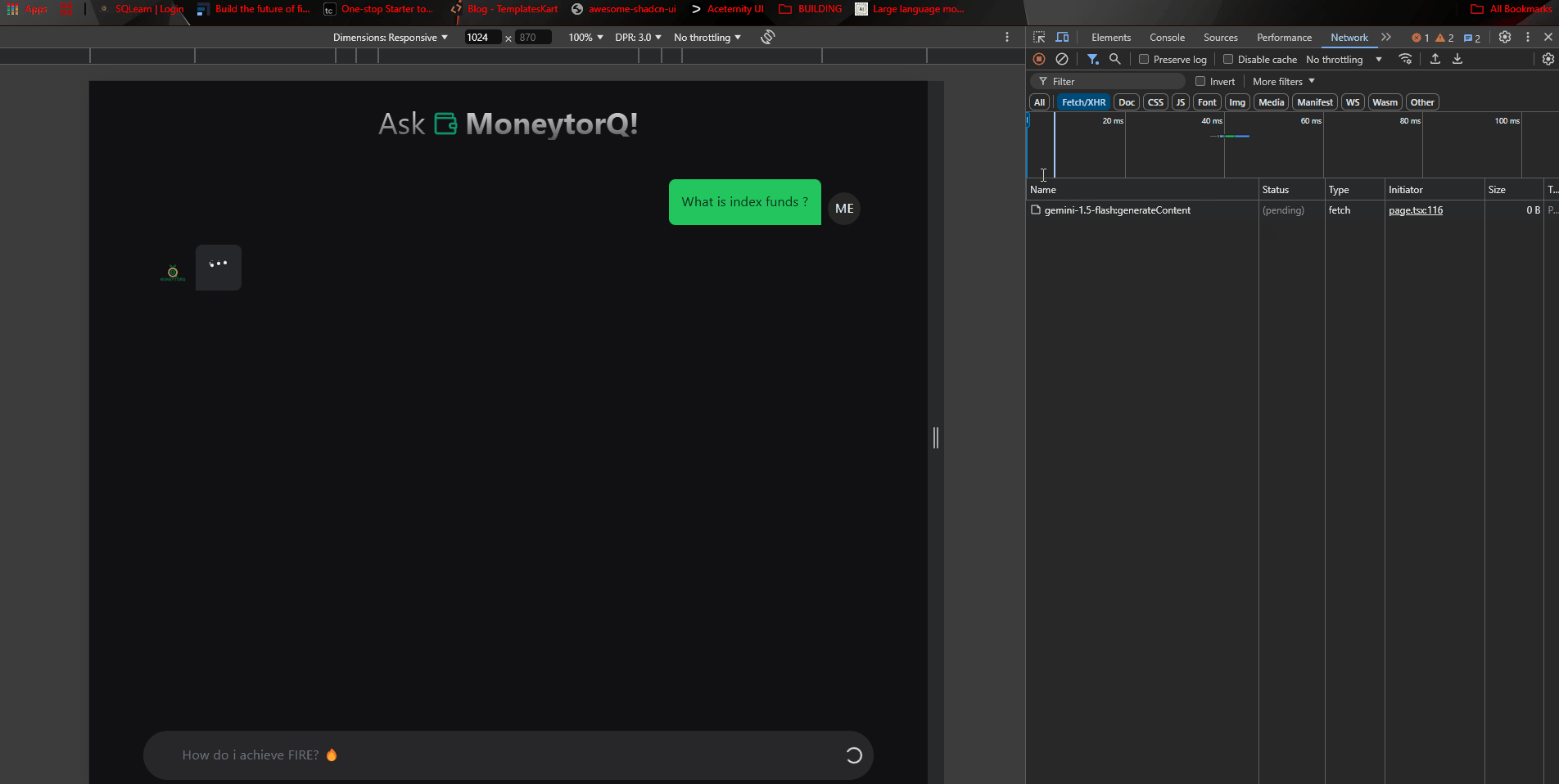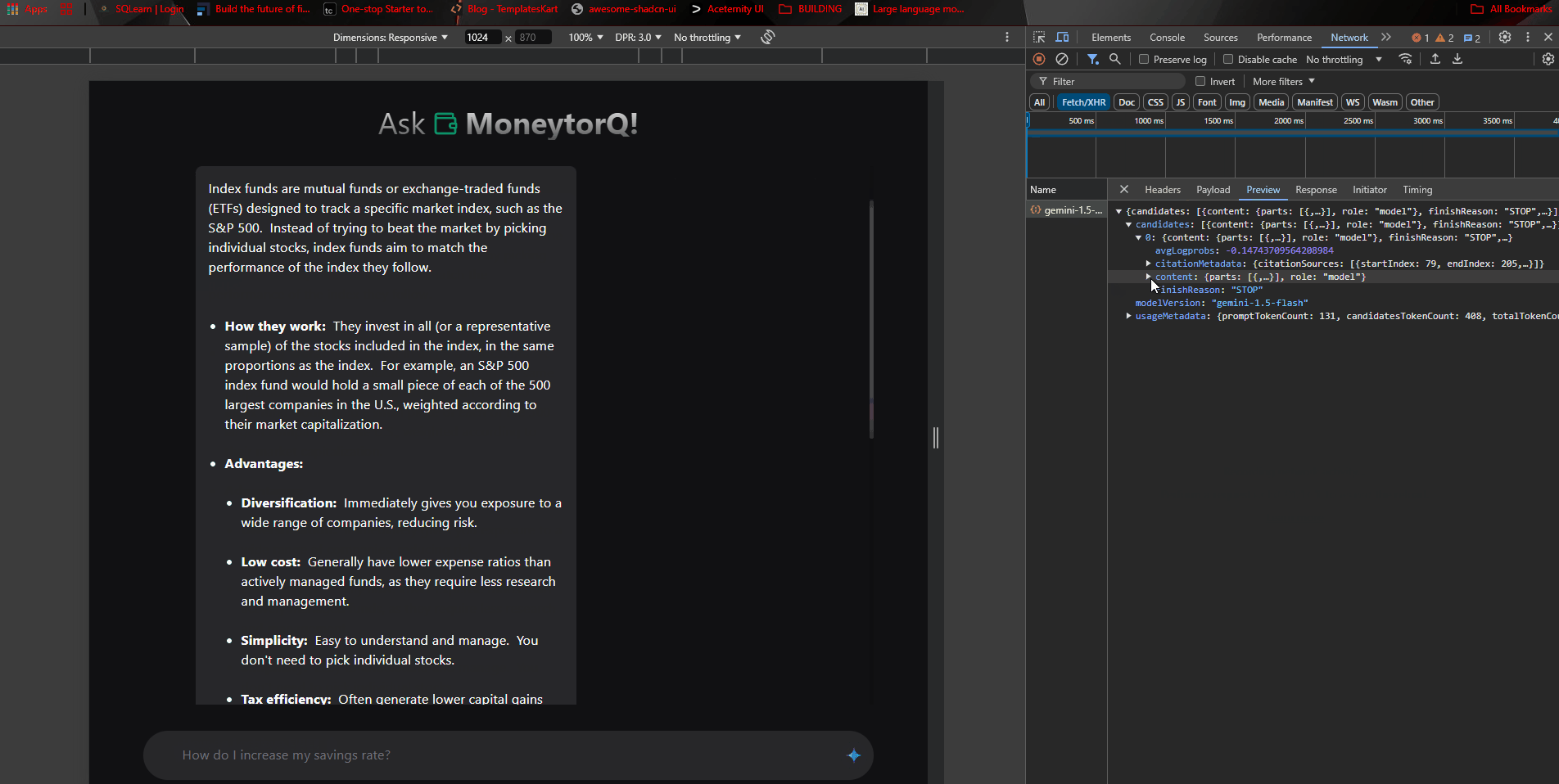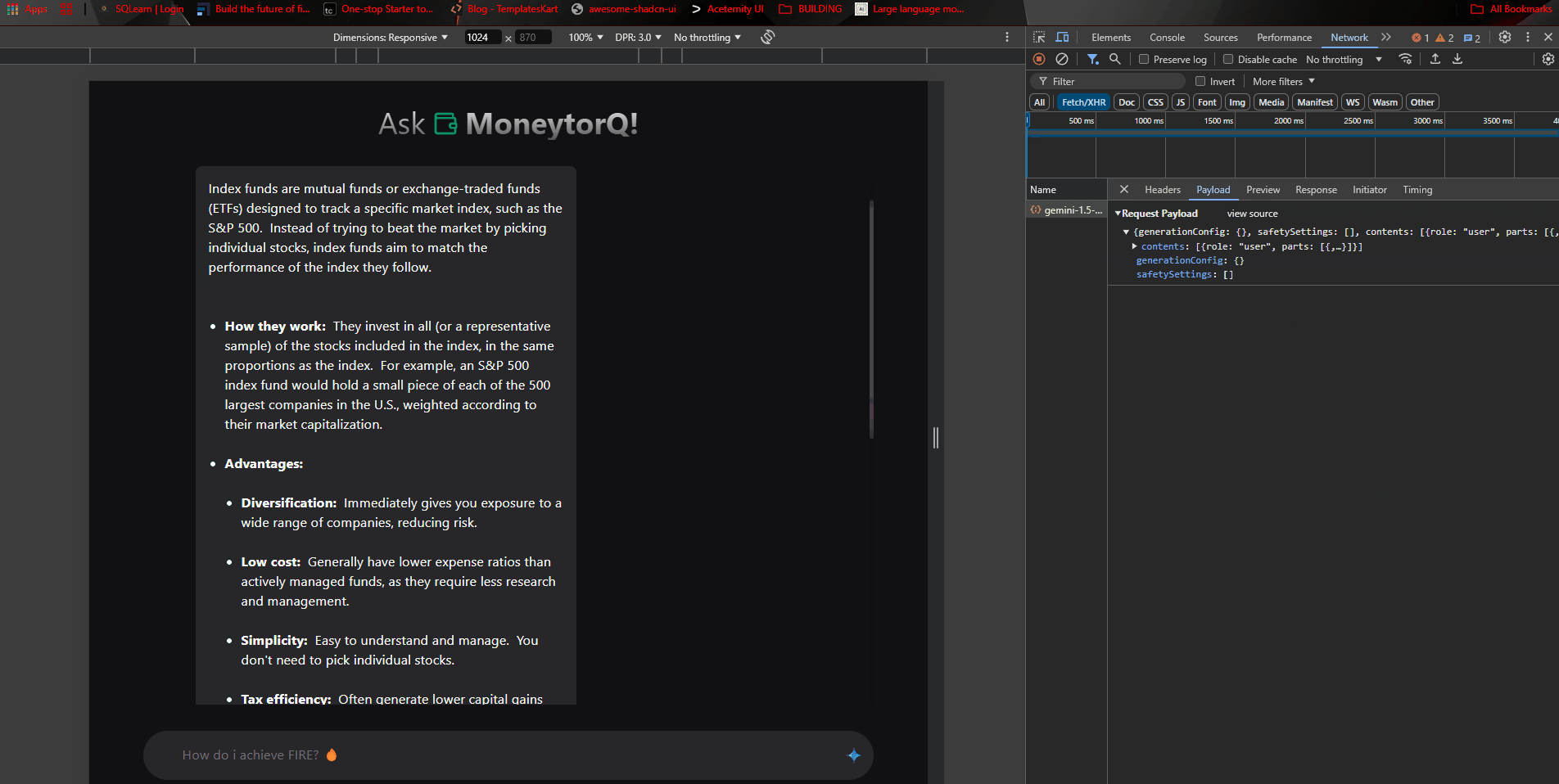
Request by the google/generative-ai works like a charm
Congratulations! By now, the app is up and running by utilizing Gemini models.
But if we remember previously we discussed how each model has its rate limits and token restrictions. Considering if we chose the Pay-as-you-go option, it’s important to ensure that your API key is not exposed.

Look at your Network Tab > Headers. Those API key is visible if we do it this way!
We need a preventive approach to how others couldn’t freely use our API key leading to slow response (because of constantly hitting the rate limit threshold) or the least favourable position: unexpected cash burns.
- Put the API Key in server environments!
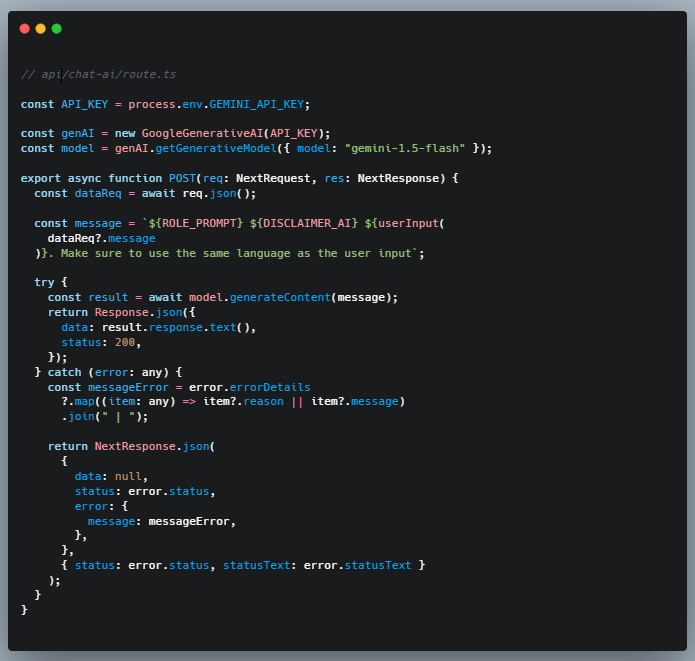
You can use Next JS Server Action to wrap it so that users won’t know your secret 🤫
There are 3 main things in how I built this function:
Putting Gemini API Key in server actions. Make sure the API Key is unexposed
Prompts I put the ROLE_PROMPT like ‘Act as Financial Advisor…’, DISCLAIMER_AI to heavily remind users that it’s generated ‘inconsistently’ depending on how the model is trained and the datasets being used therefore they need to take it with a grain of salt. And finally, the question/prompt is based on what the user inputs.
Returning it into JSON Response for generated content or errors if any
The UI/UX
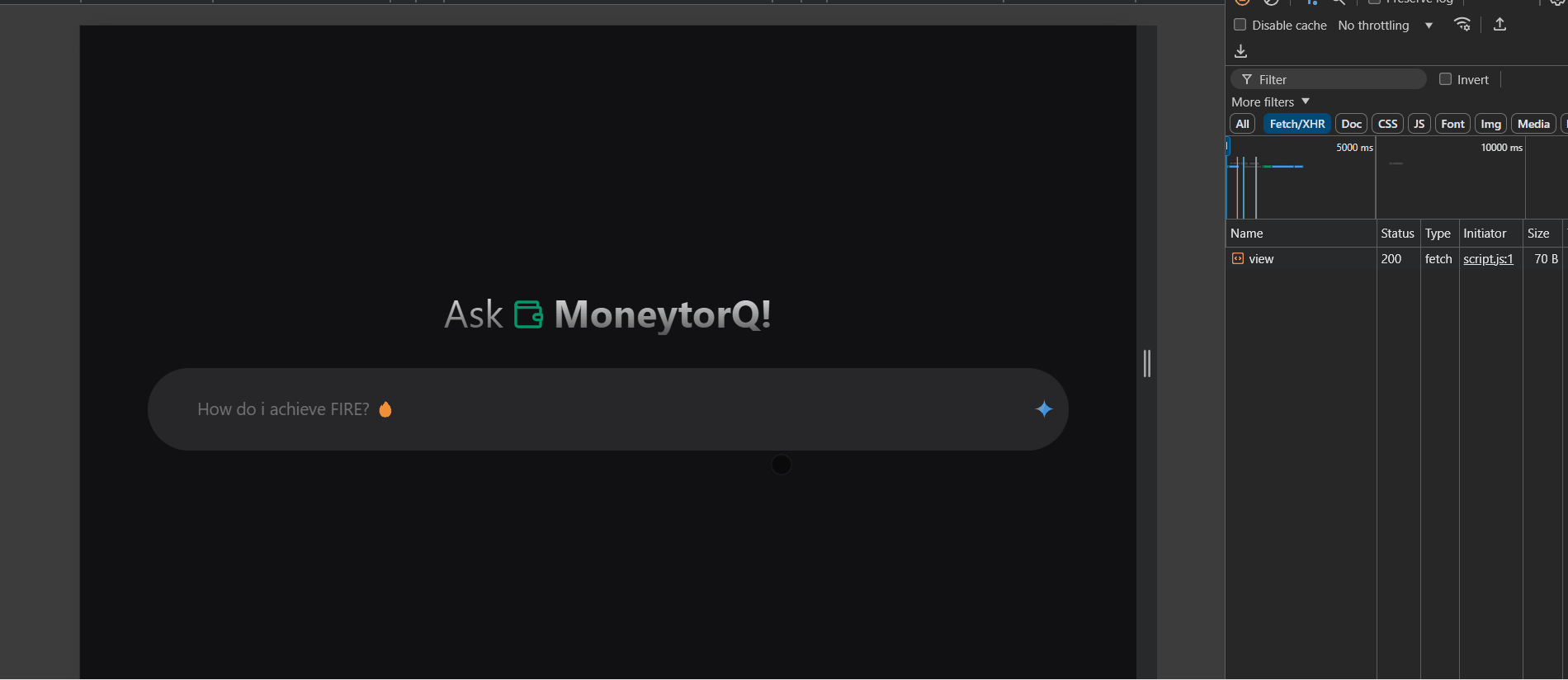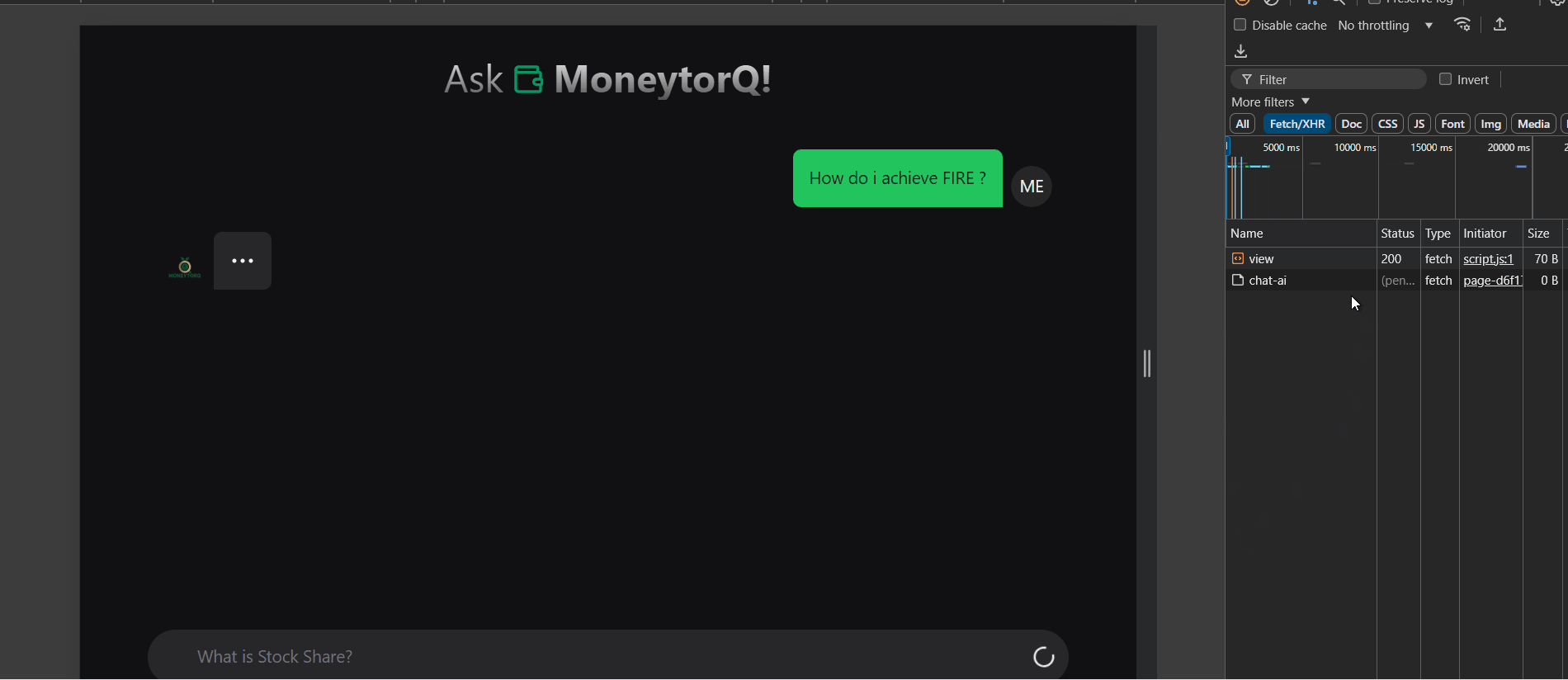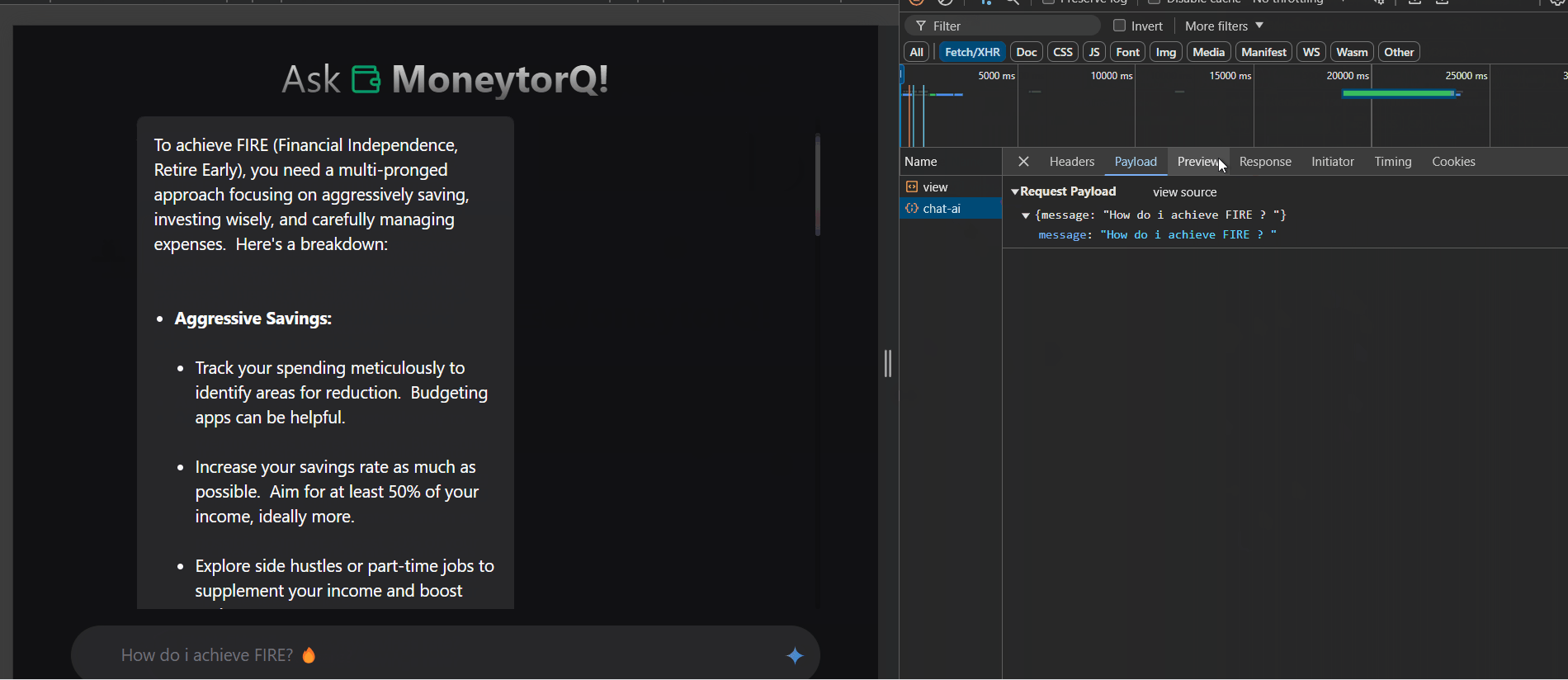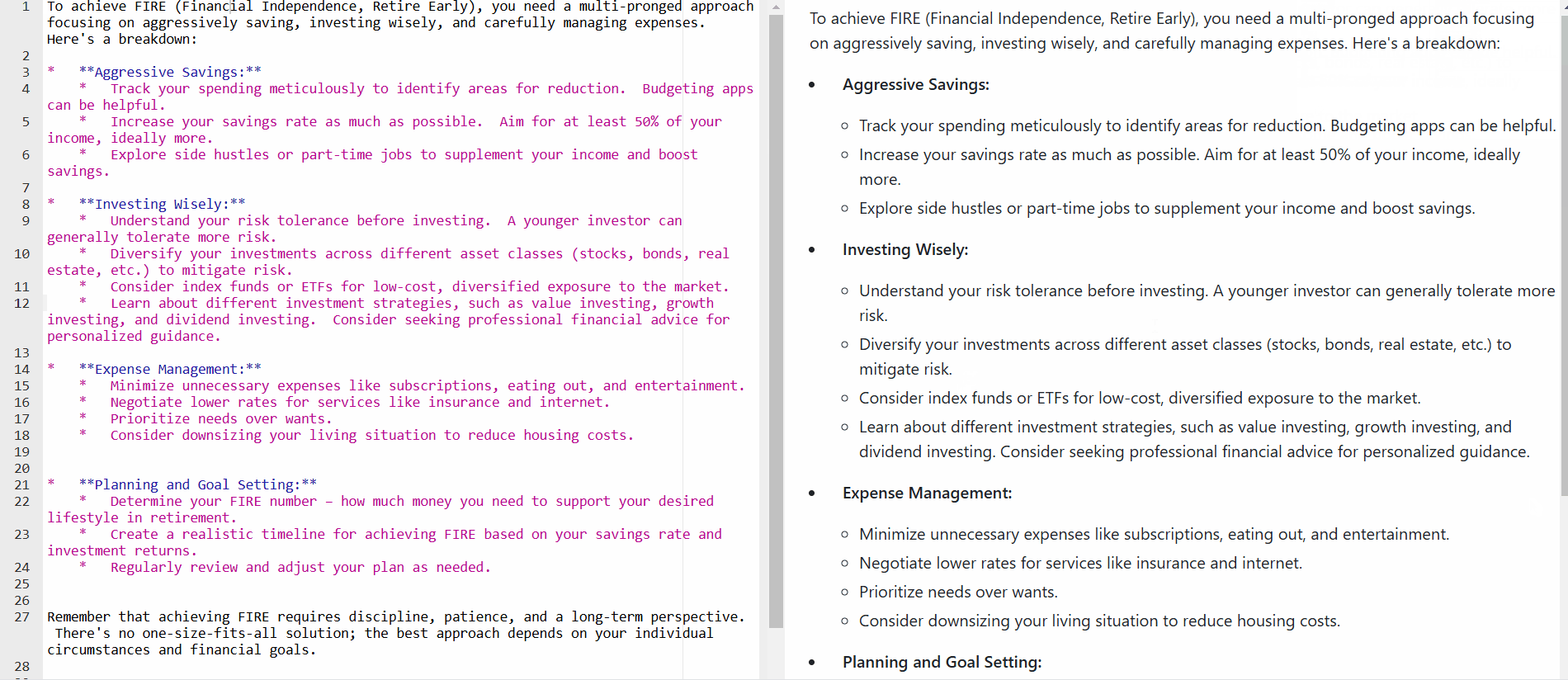
The response of Gemini API is in Markdown
Since the generated content response from Gemini API is in markdowns, we’ll need to wrap the output with your preferred library to render it properly. For ease, I’m just using React Markdown.
Last thing to consider is how we make the user flow adjusted to our free Gemini API plan. To make such constraint, the application limits the public user to make 3 request per visit and they may try again tomorrow.

3 Requests per day per user, this way the app can tolerably have some constraint to allow others to try as well
Footnote
I’m developing a personal finance tracker web app. Chat with AI feature is still on the free version of Gemini, so the Rate Limit from Google API may apply :)
With that said, feel free to check for yourself here.
Also, if you wonder how I built the backend and the database for the application, I used Supabase and talked about this in my other post!
Cheers.